1.Basic environment
Open source projects:
https://github.com/Akegarasu/lora-scripts
Required Dependencies:
Python 3.10.8
Git
2.Start using
2.1.Create a root folder:
 2.2.Extract key words, This will be done using lora-scripts built-in tools
2.2.Extract key words, This will be done using lora-scripts built-in tools
2.2.1.Create a base folder for input to keyword extraction
 2.2.2.Configure the basic data folder, and finally click to run
2.2.2.Configure the basic data folder, and finally click to run
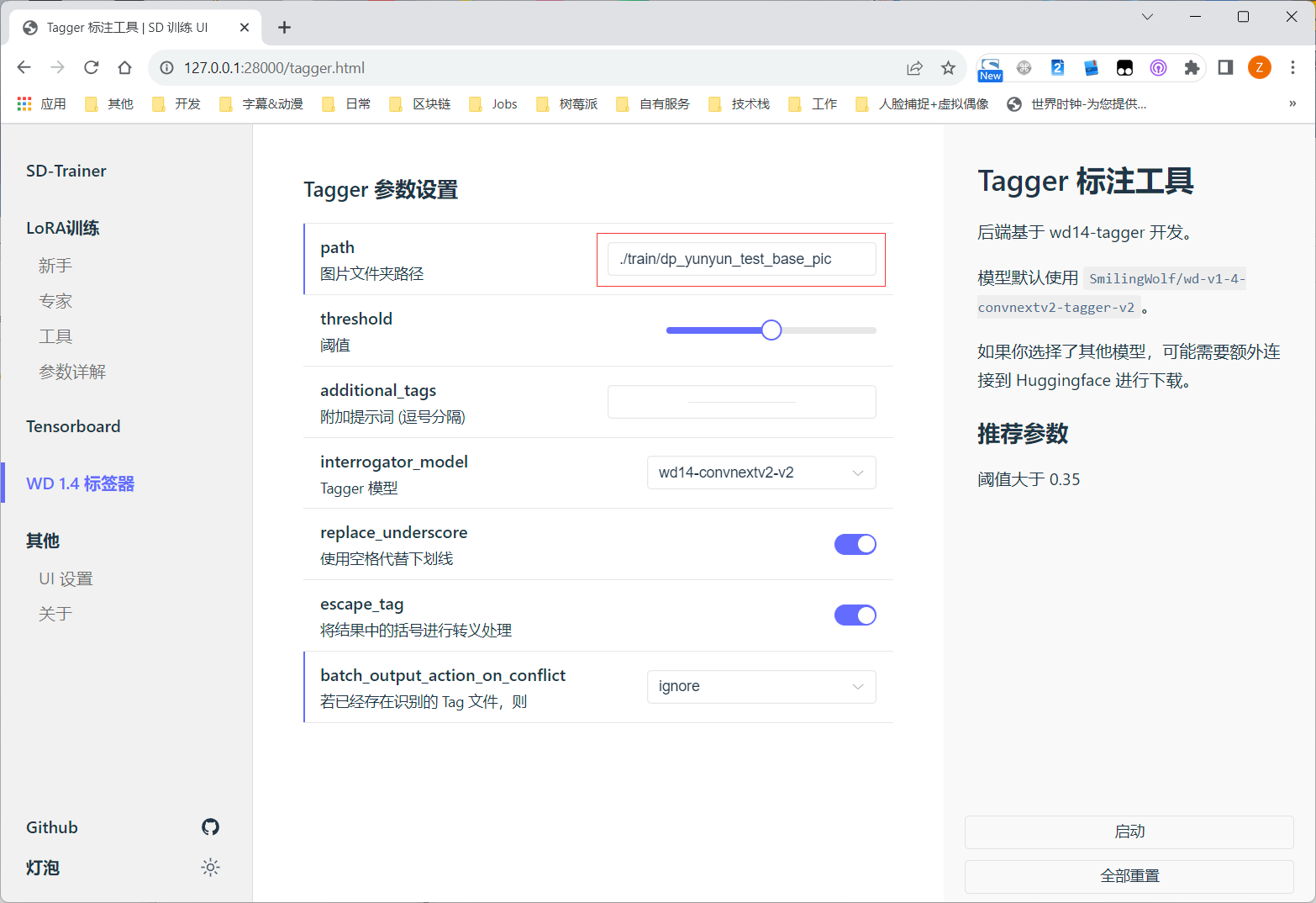
2.3.Extract key words, This will be done using the SD WebUI.
2.3.1.Create a base folder for input to keyword extraction

2.3.2.Create output folder
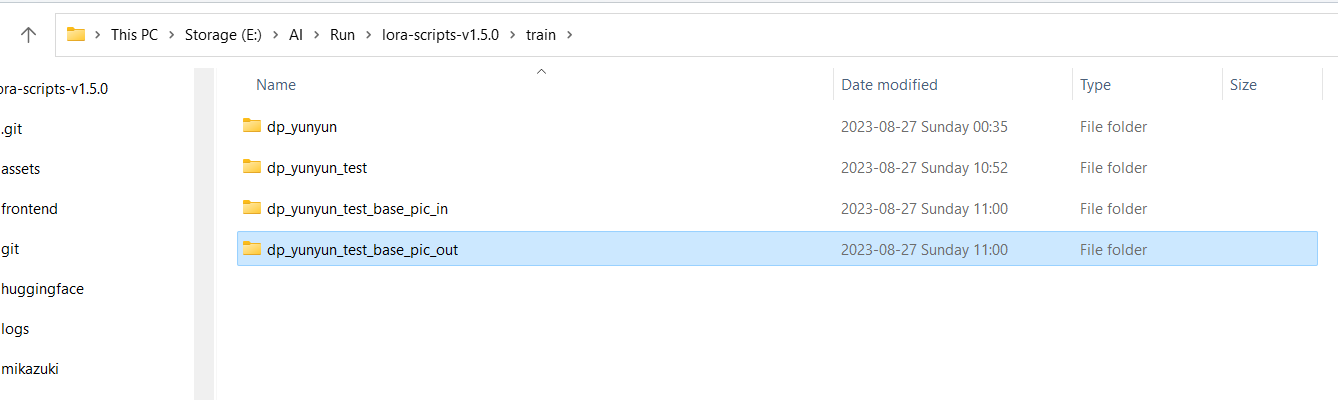 2.3.3.Create output folder
2.3.3.Create output folder
 2.3.4.Extraction complete.
2.3.4.Extraction complete.
 2.3.5.Preview output
2.3.5.Preview output
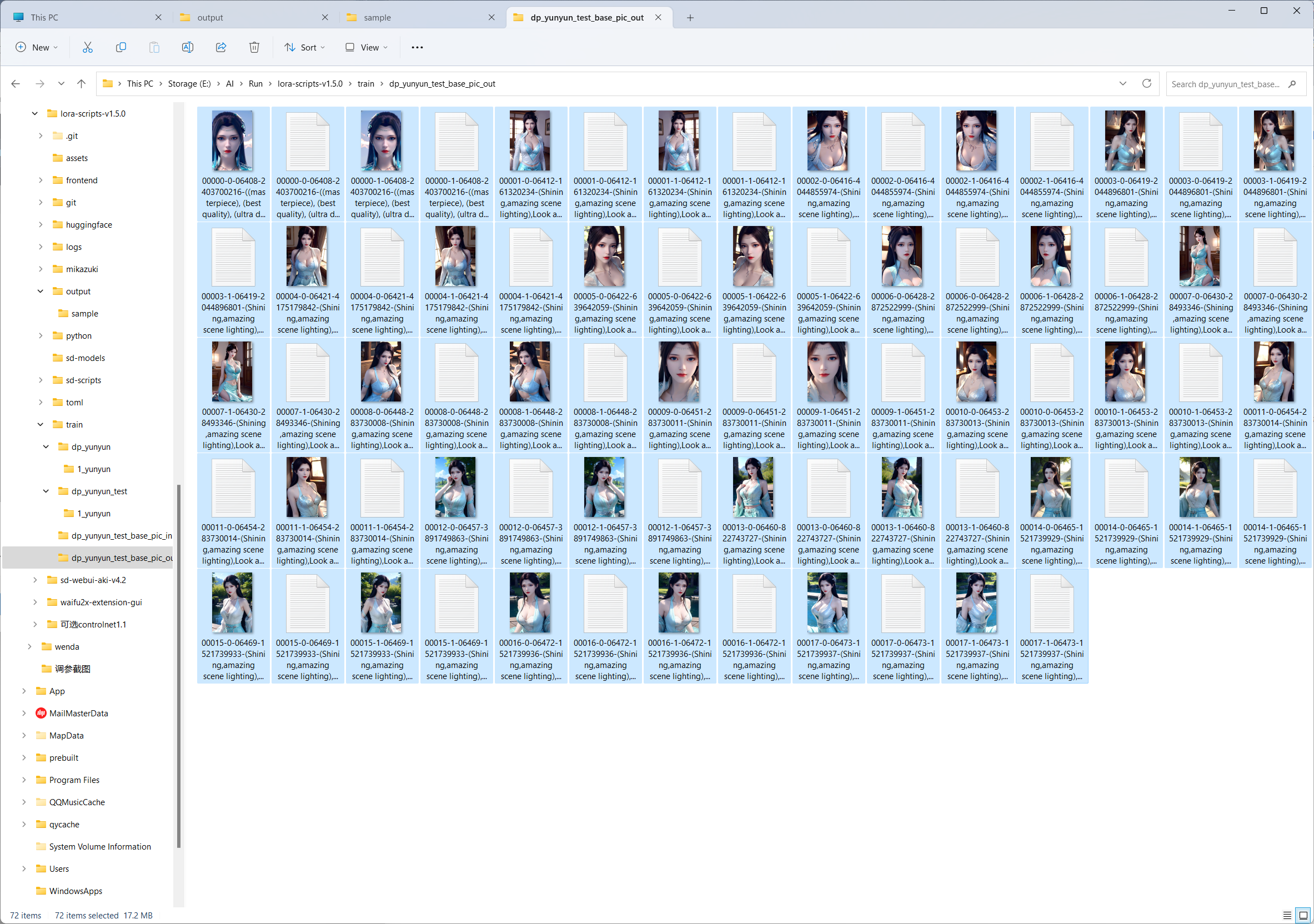
2.4.Copy all output files into a subfolder in the root directory created initially.
2.4.1.Create a basic data folder for training and classify
First of all, we need to create a subfolder. The folder name starts with a number, separated by an underscore, and ends with a tag.
Notice: The tag indicates the style of this group of pictures, which is conducive to training and reasoning.
 Put all output files.
Put all output files.
 2.5.Run lora-scripts.
2.5.Run lora-scripts.
2.5.1.update the program: run "A强制更新-国内加速.bat".
 2.5.2.After doing the above, run "A启动脚本.bat".
2.5.2.After doing the above, run "A启动脚本.bat".
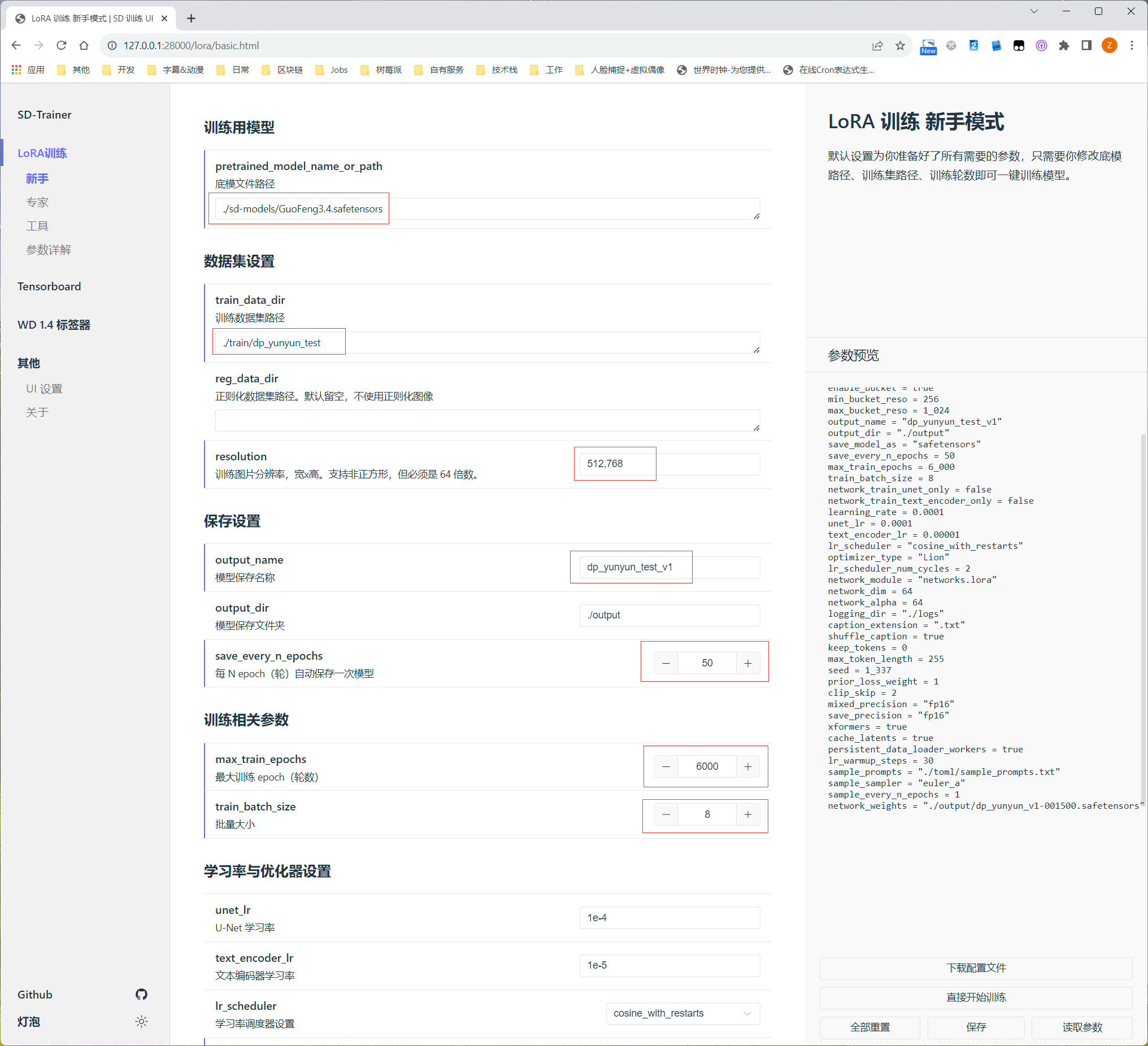
2.6.Start LoRA training.
2.5.1.Use novice mode for training, Make some changes to your personalization.
Notice:
Properly increase the configuration of "train_batch_size" according to your hardware environment.
The configuration of "lr_warmup_steps" is beneficial to improve the training quality, but it should not be too large, which is prone to overfitting.
My personal understanding: For the configuration of lr_scheduler_num_cycles, you can set 3 when the total number of training rounds is not high. In the case of many training rounds, if the value is too small, overfitting will occur. The increase of training rounds and the configuration change of lr_scheduler_num_cycles will affect the final training quality.